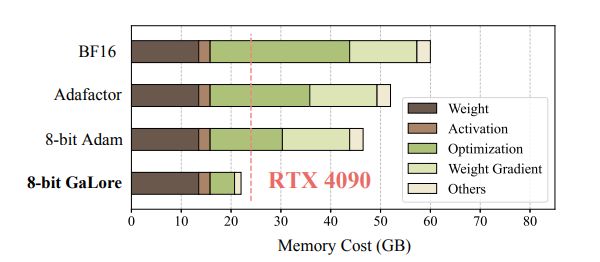
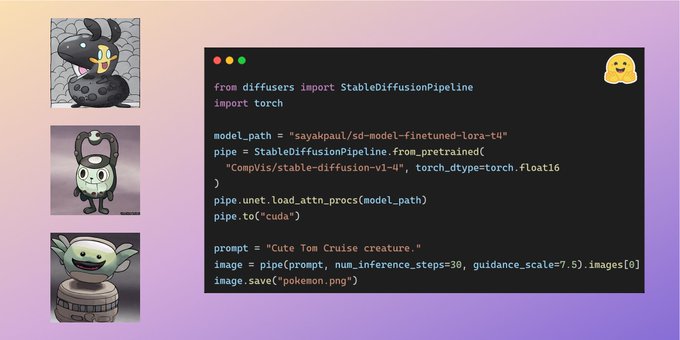
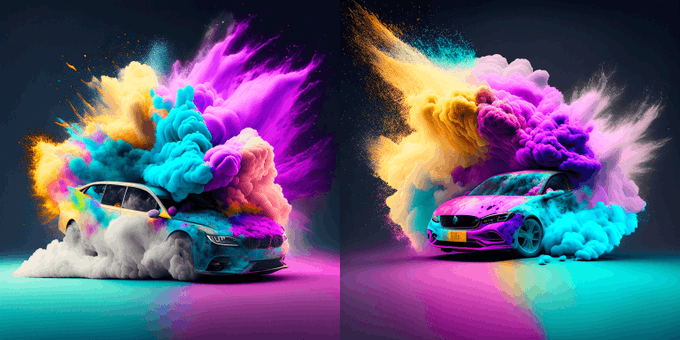Simo Ryu
@cloneofsimo
3,776
Followers
431
Following
330
Media
1,231
Statuses
I like cats, math and codes cloneofsimo @gmail .com
Don't wanna be here?
Send us removal request.