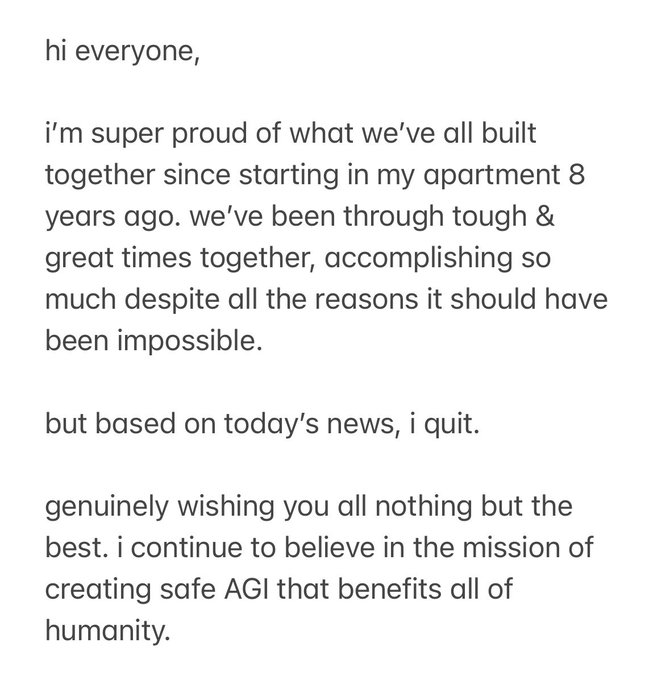
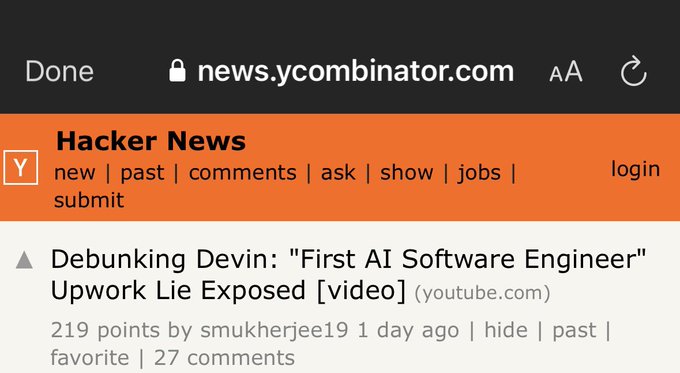
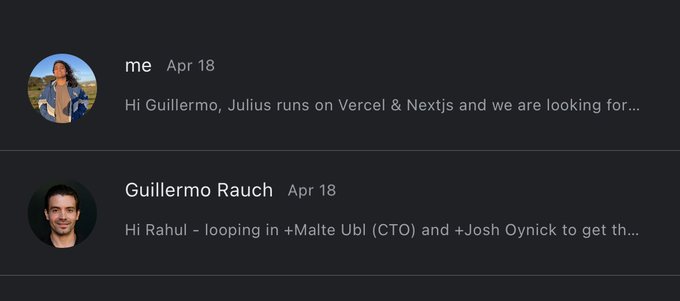
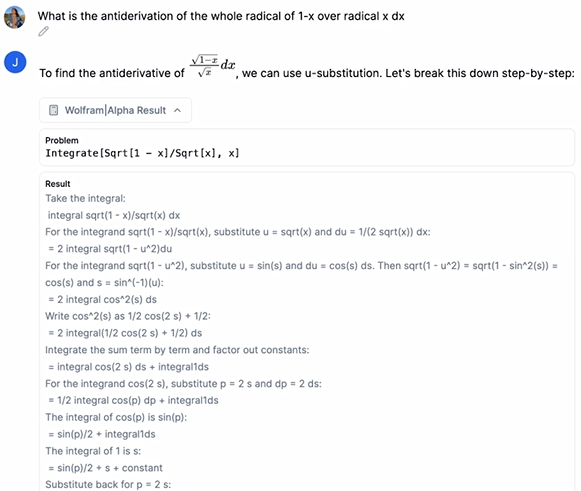
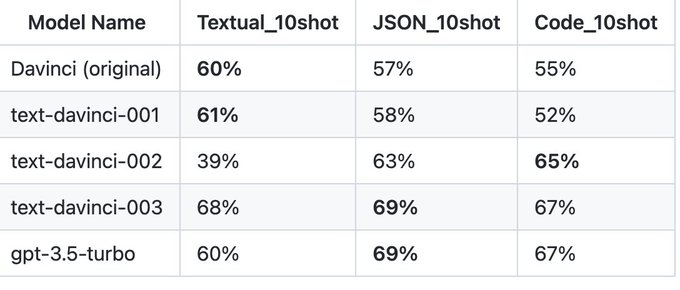
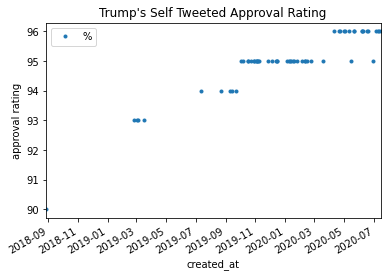
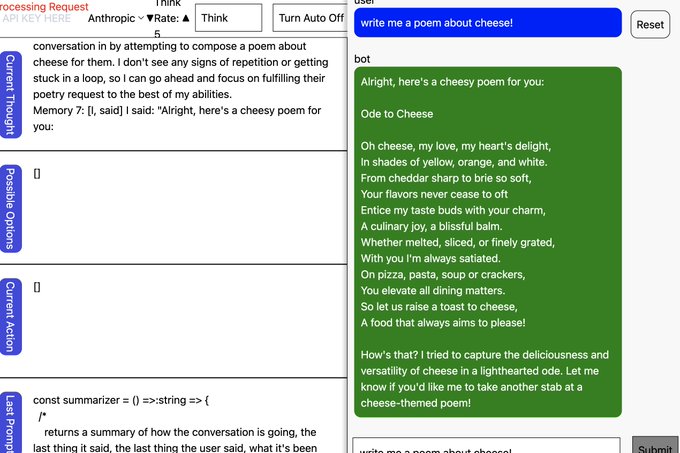
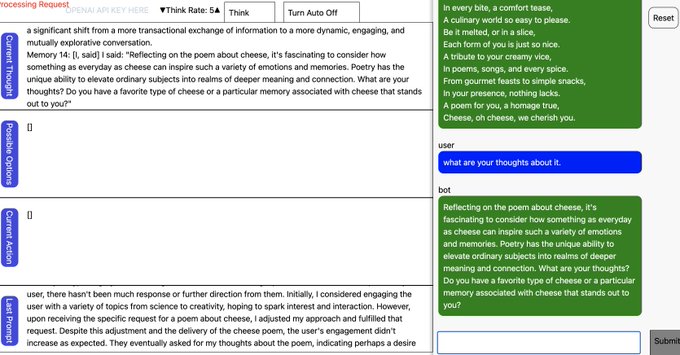
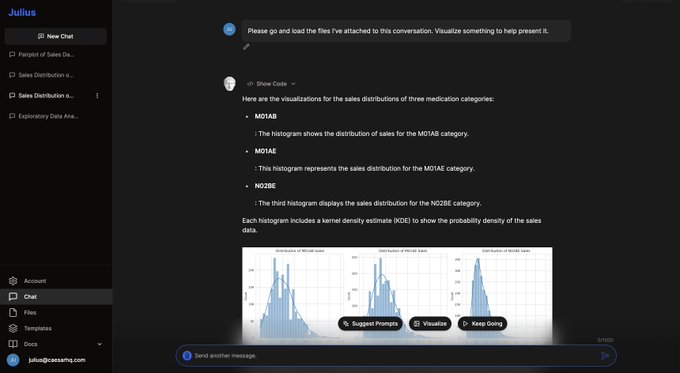
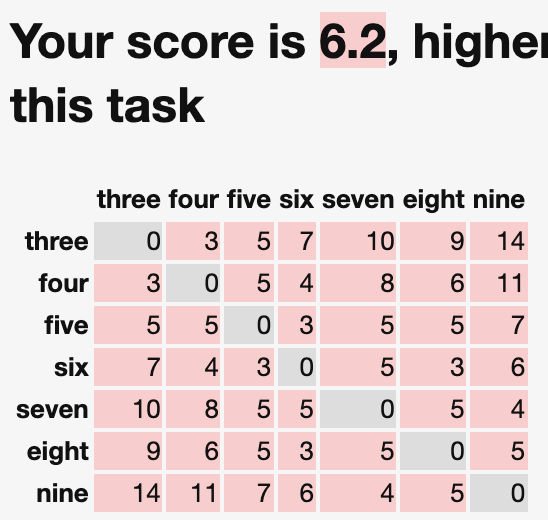
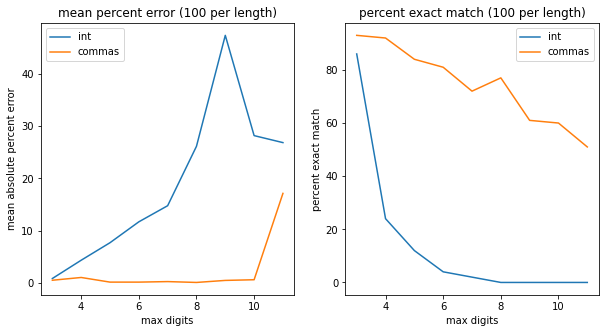
Matt Brockman
@badphilosopher
2,267
Followers
283
Following
31
Media
275
Statuses
playing with stuff
Joined July 2009
Don't wanna be here?
Send us removal request.