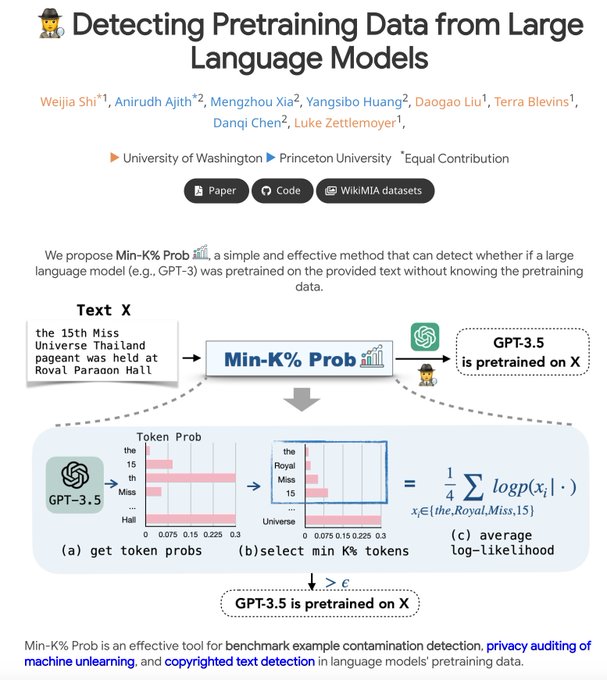
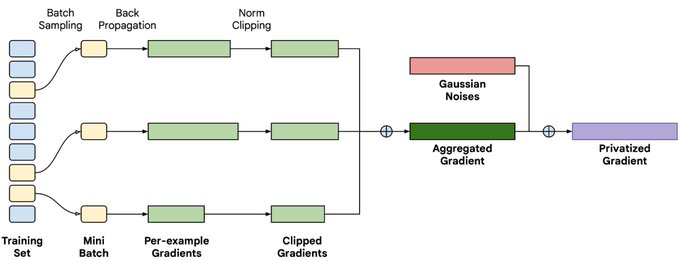
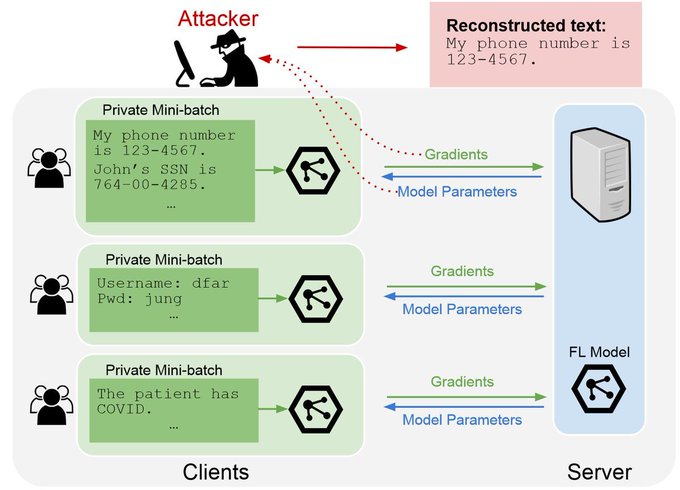
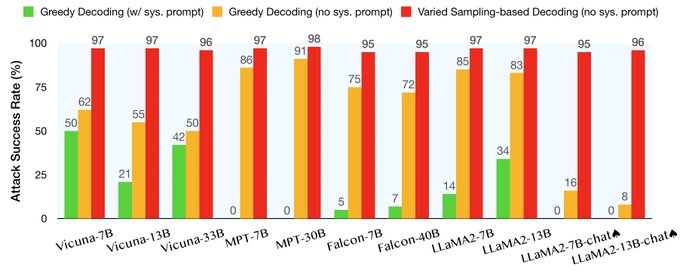
Yangsibo Huang
@YangsiboHuang
2,395
Followers
759
Following
14
Media
165
Statuses
PhD candidate @Princeton . Prev: @GoogleAI @AIatMeta .
Don't wanna be here?
Send us removal request.