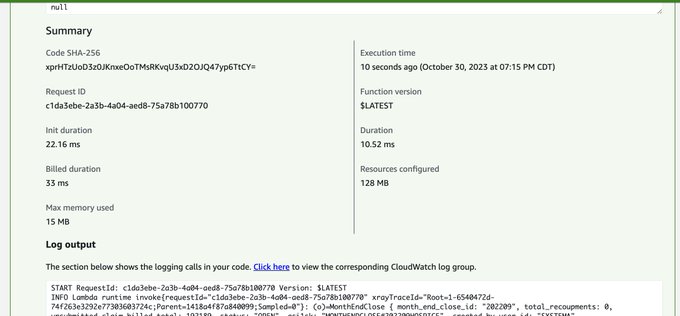
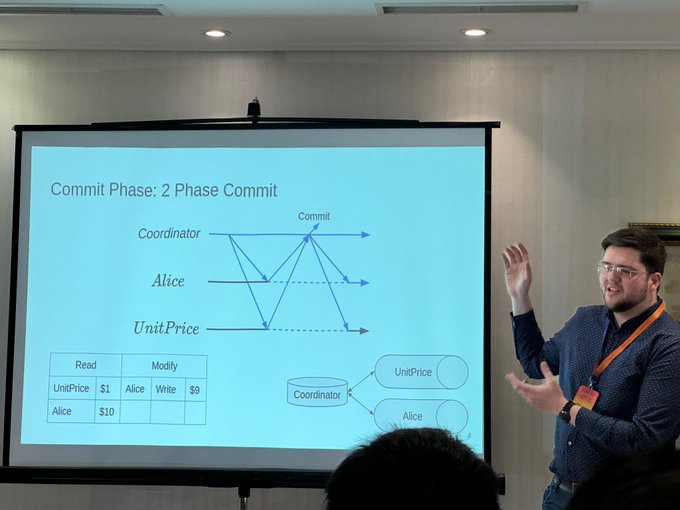
Marc Brooker
@MarcJBrooker
17,368
Followers
748
Following
255
Media
2,005
Statuses
AI, databases, and serverless at AWS. Views are my own. On Mastodon: @marcbrooker @fediscience .org
Joined October 2013
Don't wanna be here?
Send us removal request.