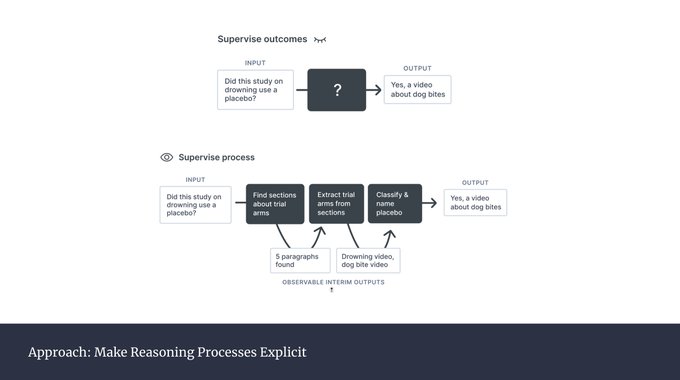
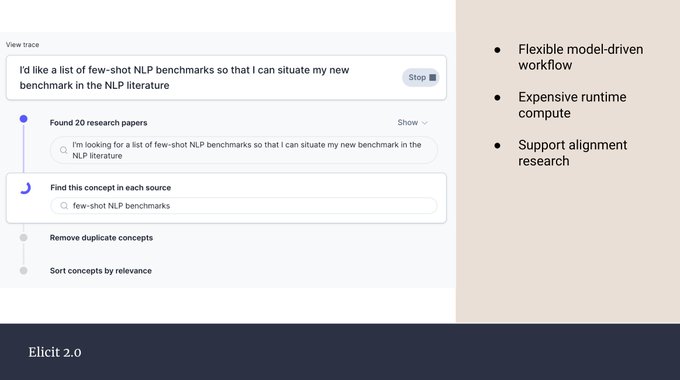
Andreas Stuhlmüller
@stuhlmueller
2,438
Followers
175
Following
124
Media
599
Statuses
scale up good reasoning @elicitorg work with me:
Don't wanna be here?
Send us removal request.