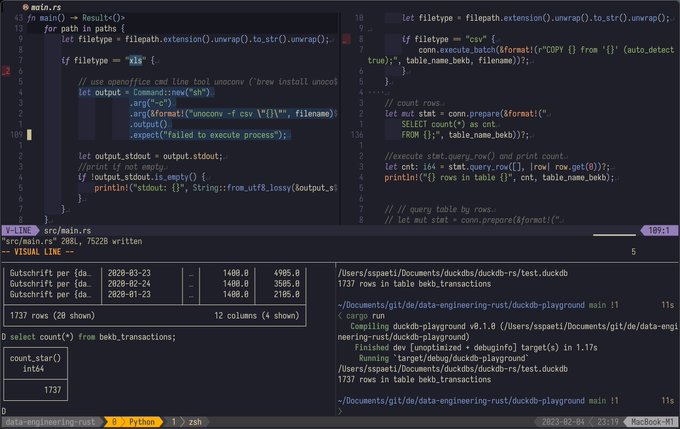
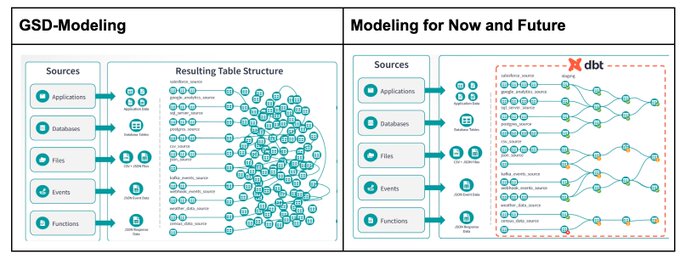
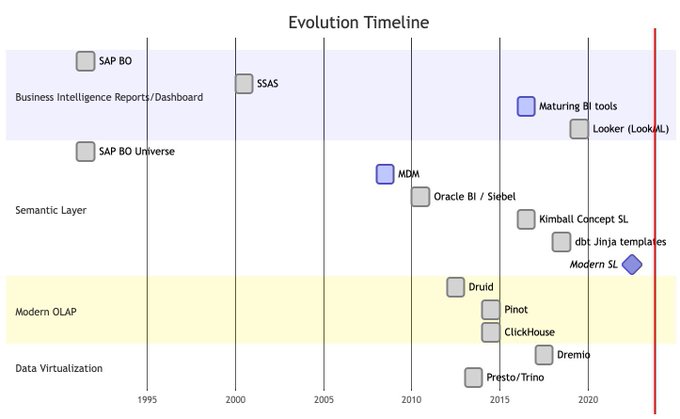
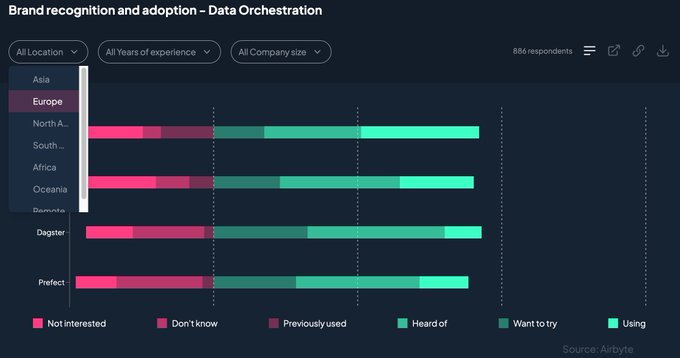
Simon Späti 🏔️
@sspaeti
2,967
Followers
1,161
Following
794
Media
3,519
Statuses
Dad. Technical Author, Data Engineer and Educator , . Tweets mostly: #dataengineering , #opensource , #writing , #pkm and #neovim
Don't wanna be here?
Send us removal request.