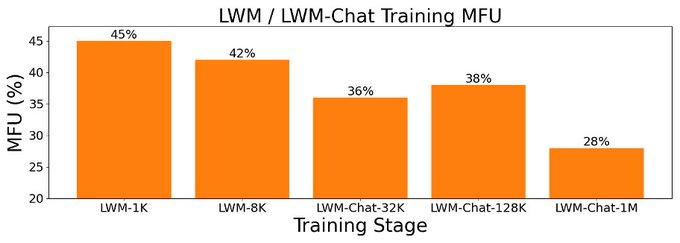
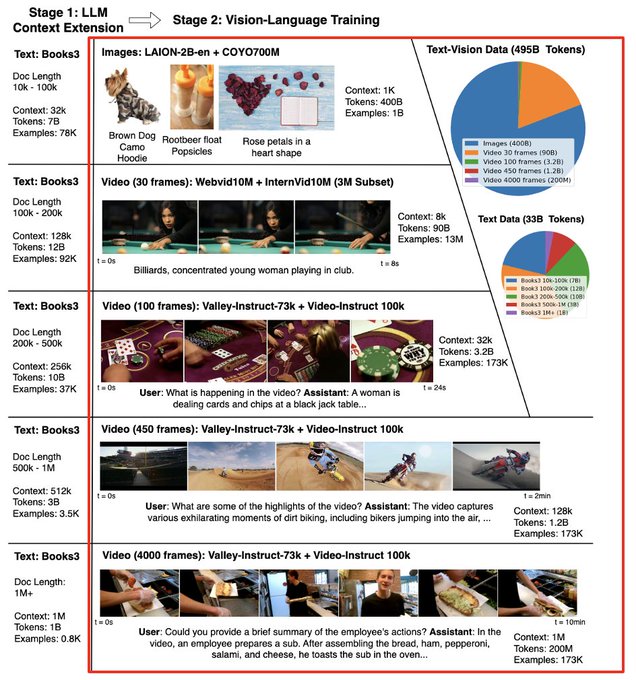
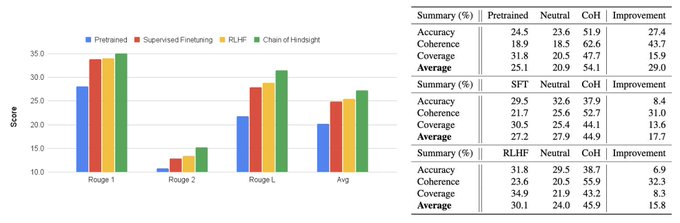
Hao Liu
@haoliuhl
4,204
Followers
156
Following
98
Media
267
Statuses
phd student @berkeley_ai machine learning, neural networks.
Joined September 2018
Don't wanna be here?
Send us removal request.