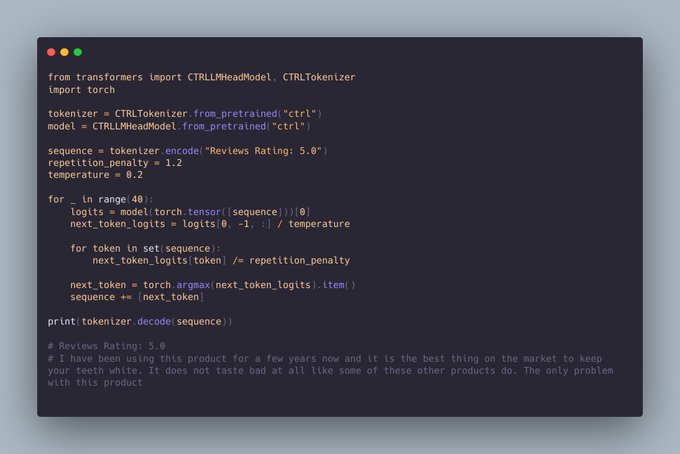
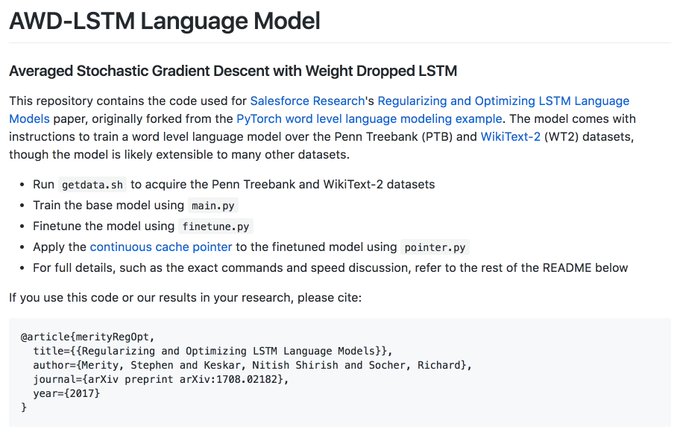
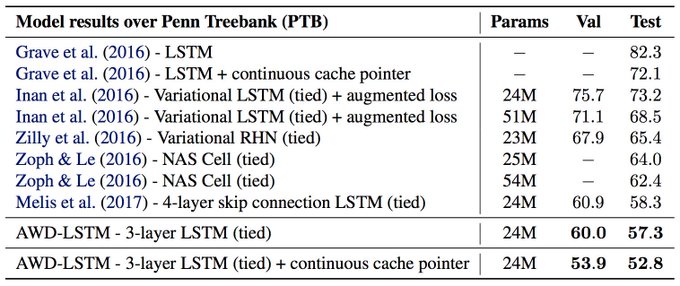
Nitish
@StrongDuality
3,127
Followers
1,018
Following
25
Media
359
Statuses
language modeling research @OpenAI | views are my own
Don't wanna be here?
Send us removal request.