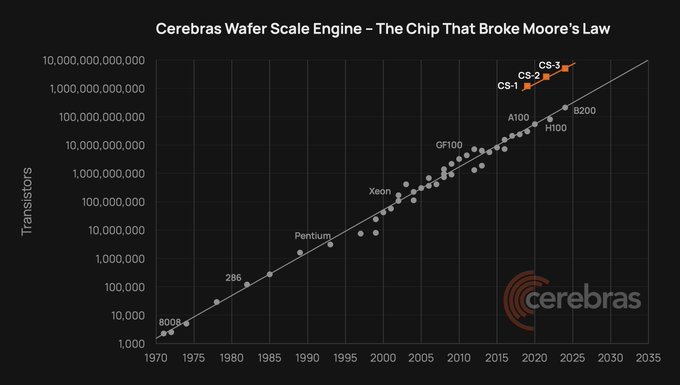
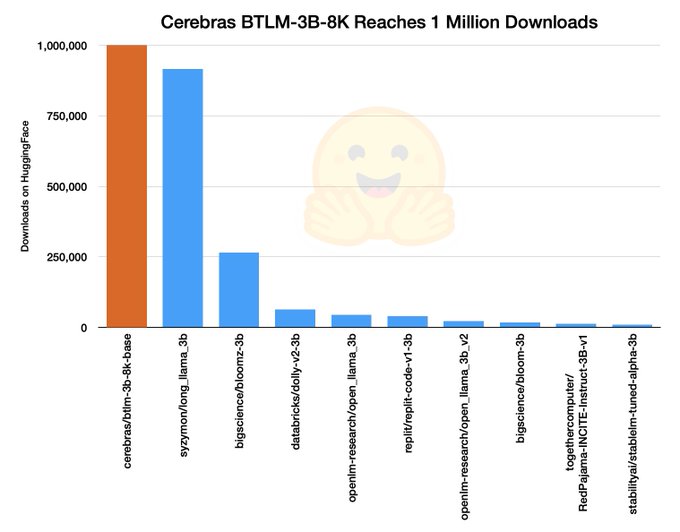
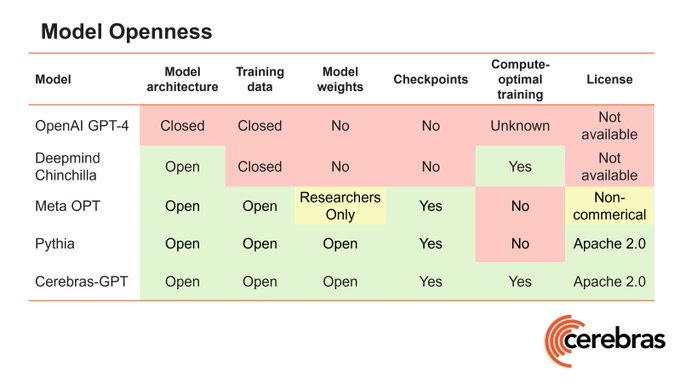
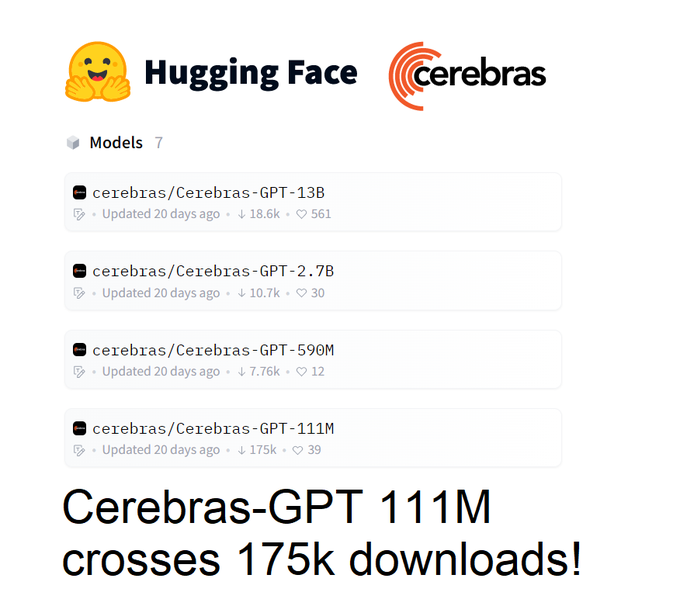
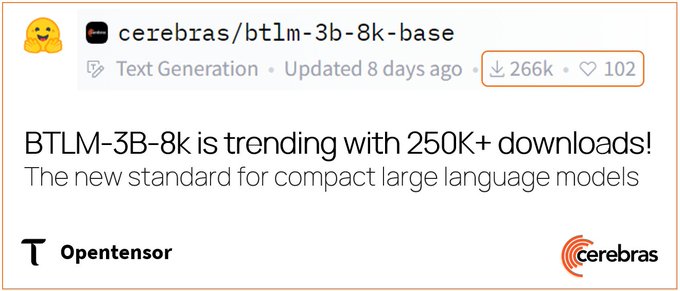
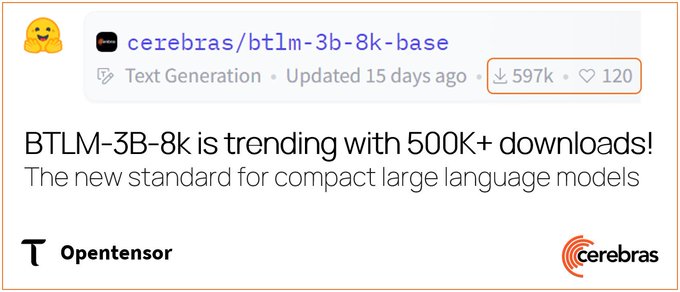
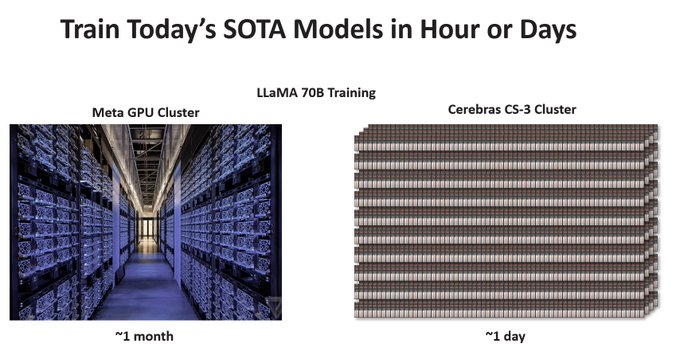
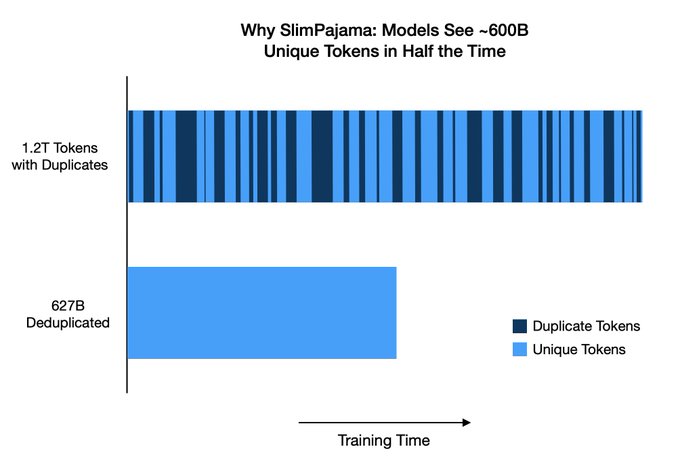
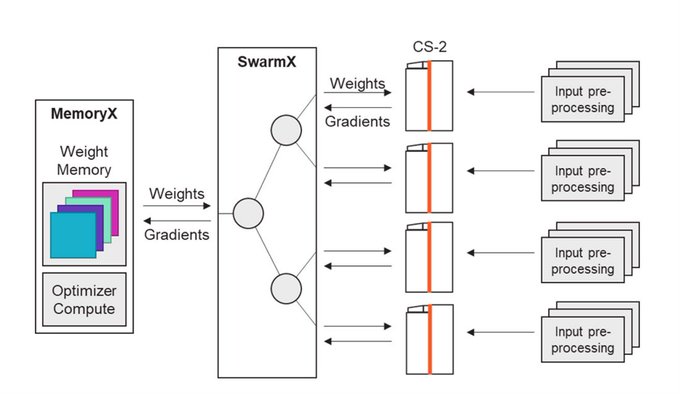
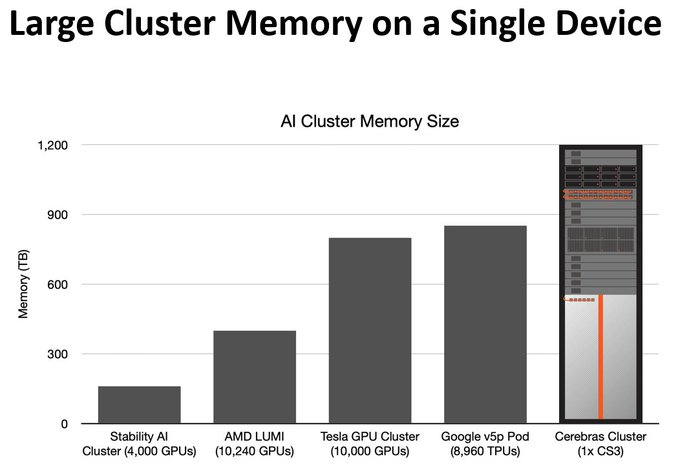
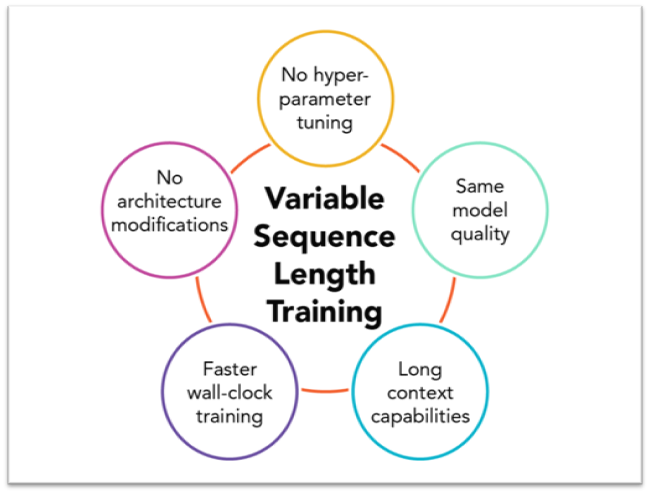
Cerebras
@CerebrasSystems
10,858
Followers
239
Following
588
Media
1,349
Statuses
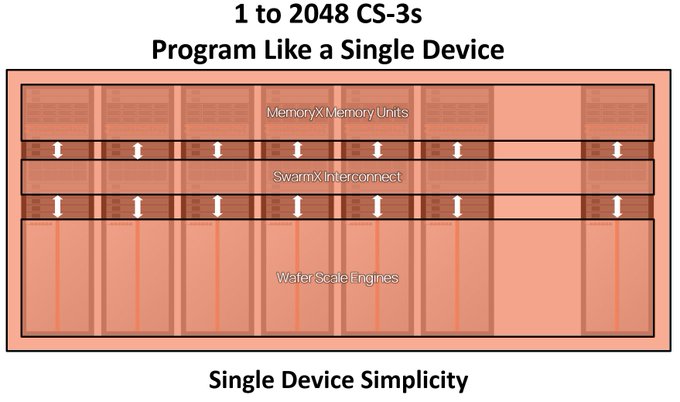
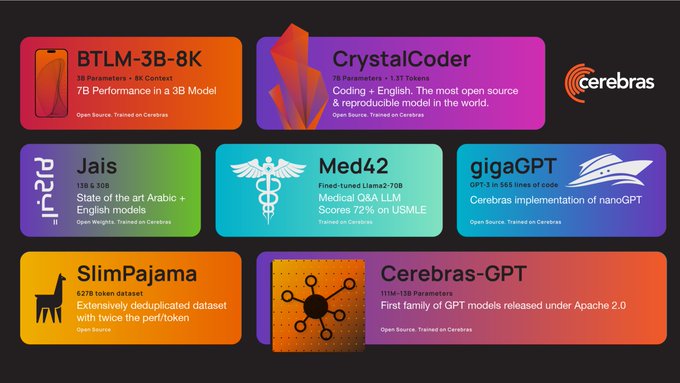
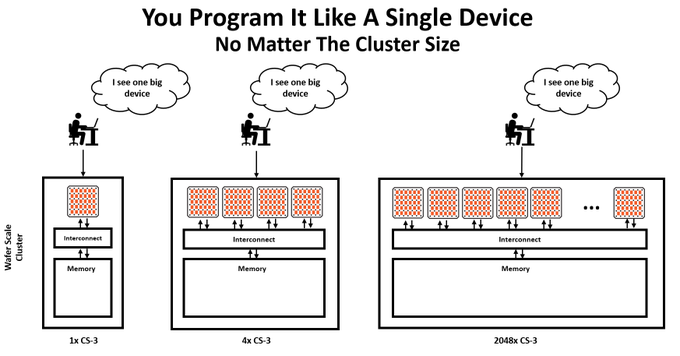
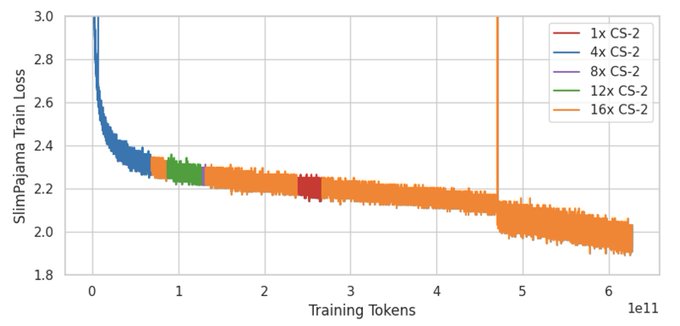
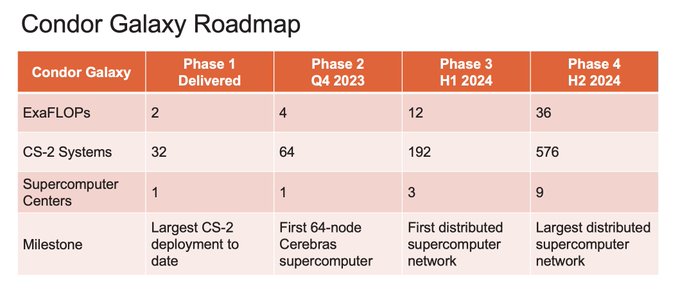
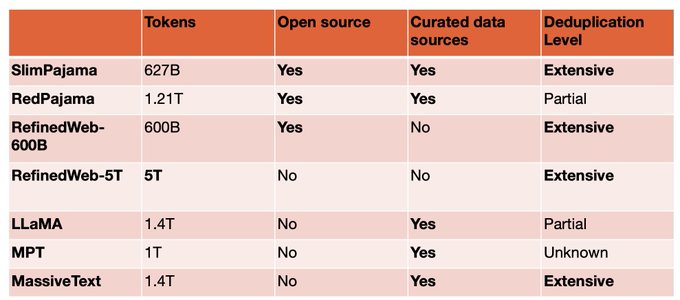
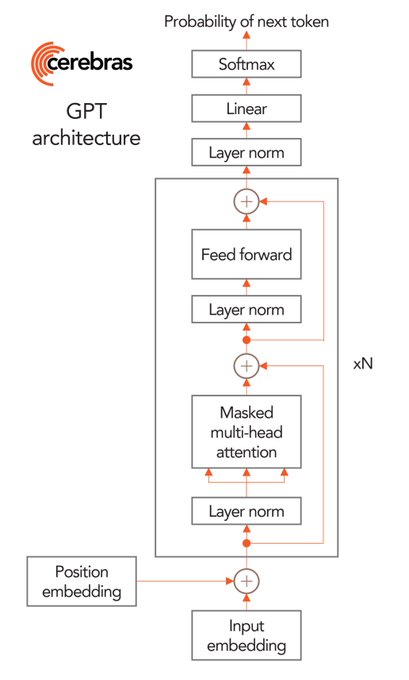
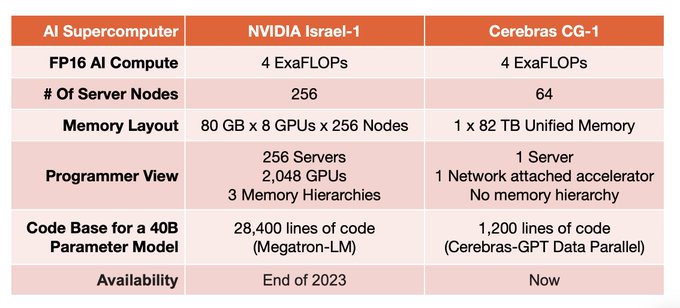
Exaflops of AI compute that programs like a single accelerator. Try our models:
Don't wanna be here?
Send us removal request.