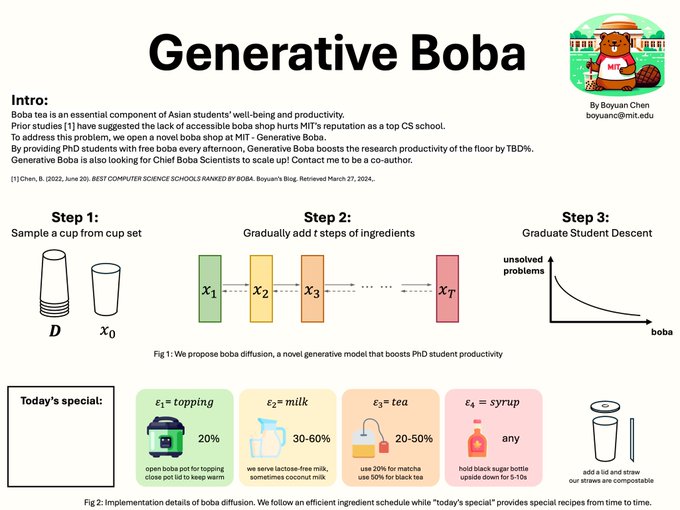
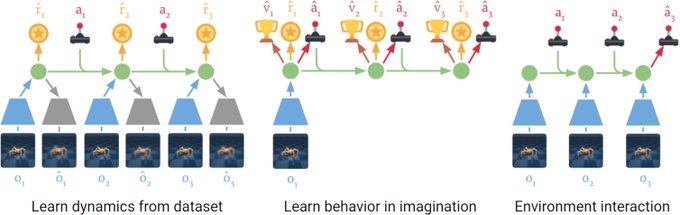
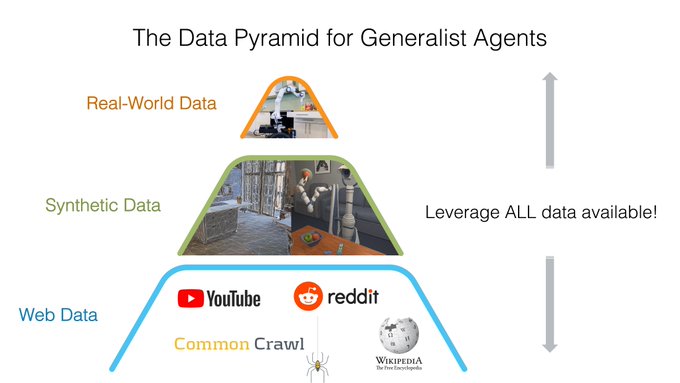
Boyuan Chen
@BoyuanChen0
1,668
Followers
293
Following
15
Media
115
Statuses
PhD student @MIT_CSAIL @MITEECS , Ex @GoogleDeepMind , @berkeley_ai ; Doing AI & Robotics. Foundational model for decision making. World models and robotics.
Don't wanna be here?
Send us removal request.