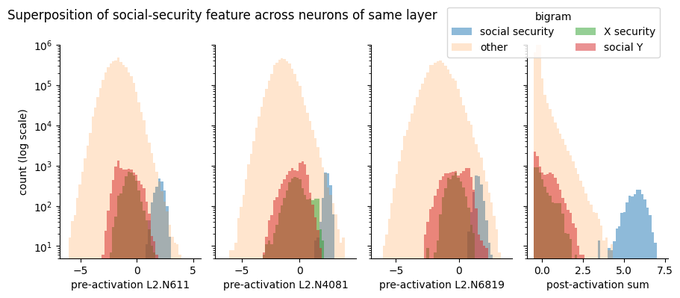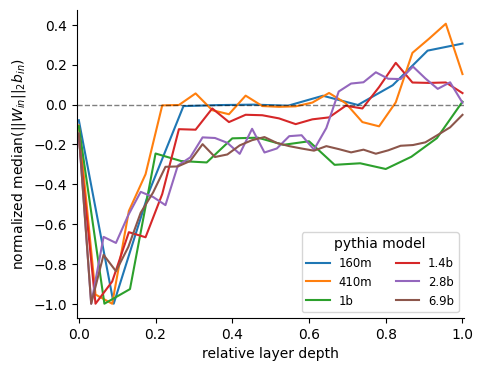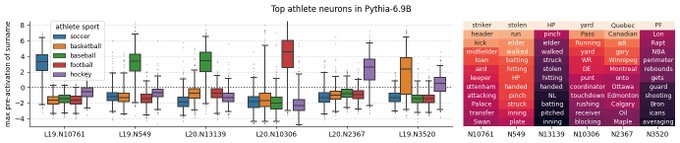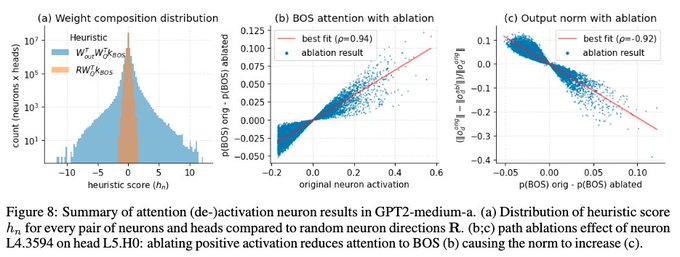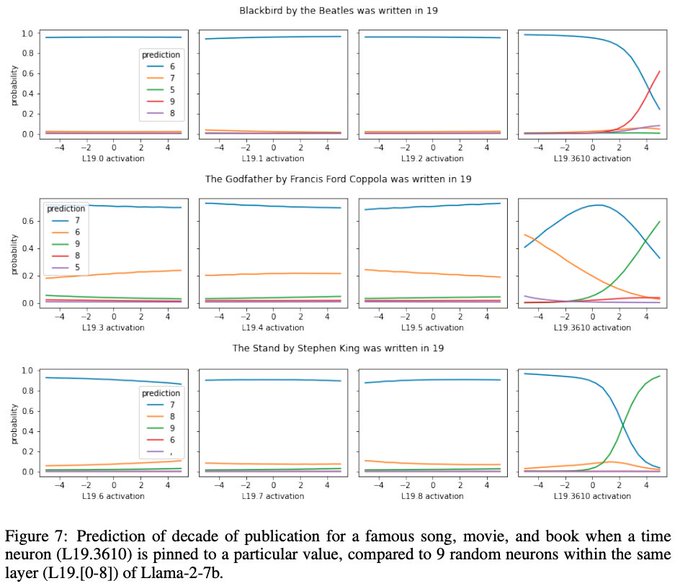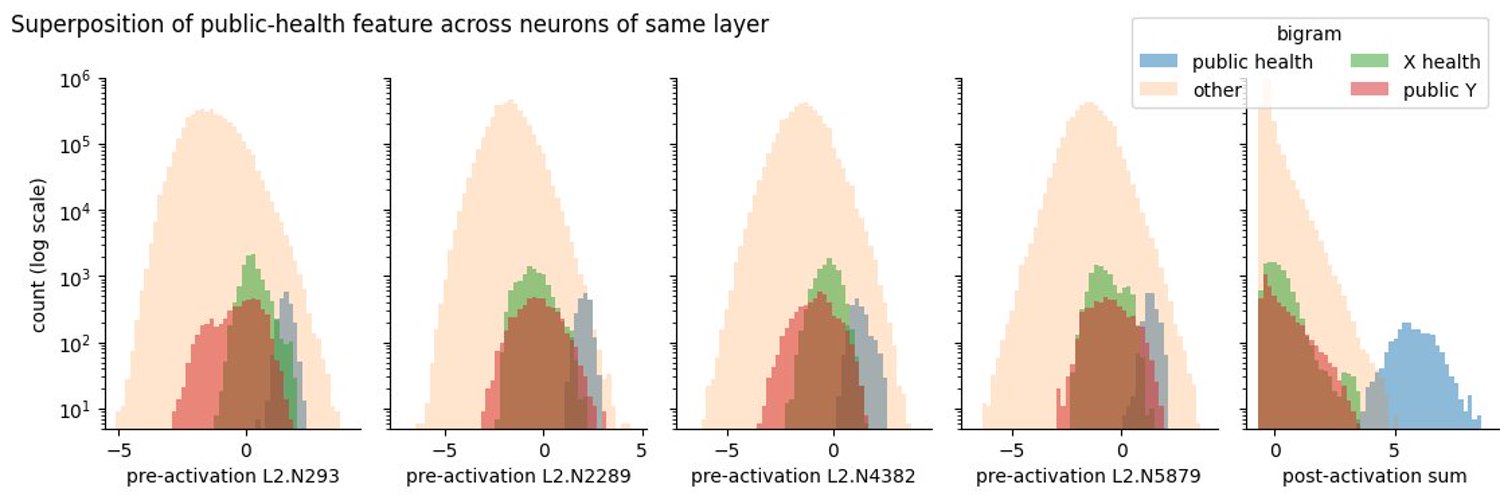

Wes Gurnee
@wesg52
3,073
Followers
198
Following
31
Media
103
Statuses
Optimizer @MIT @ORCenter PhD student thinking about Mechanistic Interpretability, Optimization, and Governance.
Don't wanna be here?
Send us removal request.