
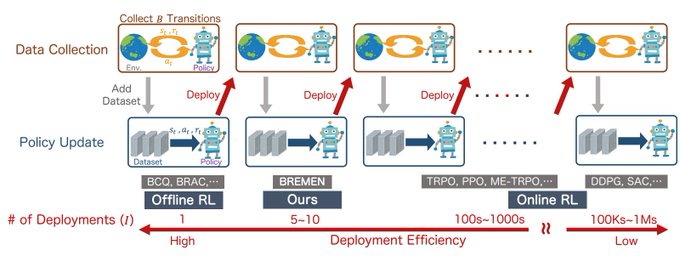
Can we solve Gym tasks with only 5-10 "trials"? Yes we can. We propose deployment efficiency as a new metric for RL, counting # of distinct data collection policies in learning. Most prior methods use 100s-1Ms. Joint w/
@Matsuo_Lab
@ofirnachum
1/
4
57
290
Replies
Deployment efficiency matters for real-world RL (e.g. healthcare, robotics, education, dialog systems) where policies likely need to be tested for safety and quality before being deployed for use or learn. It is therefore an important (but previously ignored) measure for RL. 2/
2
2
12
Our building block, BREMEN, is a simple model-based offline RL method that works even with 10-20x less data (model-free fails). Also check out 2 concurrent model+offline works
@svlevine
@chelseabfinn
@tengyuma
and
@aravindr93
3/

1
2
15
Congratulations to
@__tmats__
@frt03_
for getting this done! And thanks to
@ymatsuo
for his support! 4/
1
1
3
Open-source code: 5/
0
1
4

@shaneguML
@Matsuo_Lab
@ofirnachum
Might be also worth checking the game-MBRL paper, and in particular the MAL algorithm (). We mainly went for sample complexity, but MAL still solved gym tasks in ~ 15 deployments. Better results possible with hyperparam specialized to min. deployments.

1
0
3
1
0
0
@le_roux_nicolas
@Matsuo_Lab
@ofirnachum
@CriteoAILab
Thanks for the reference!! I actually remember reading this paper :) We took model-based approach, but indeed PoWER, RWR, AWR-like algorithms are also likely suited for good offline and deployment-efficient performance. Hope to see more work in this direction!
0
0
0
@shaneguML
@Matsuo_Lab
@ofirnachum
Nice work Shane! Number of policy changes is an important metric. We also argue in our MOReL paper that one main advantage to offline RL is to view standard RL as a sequence of batch problems.
0
0
1
