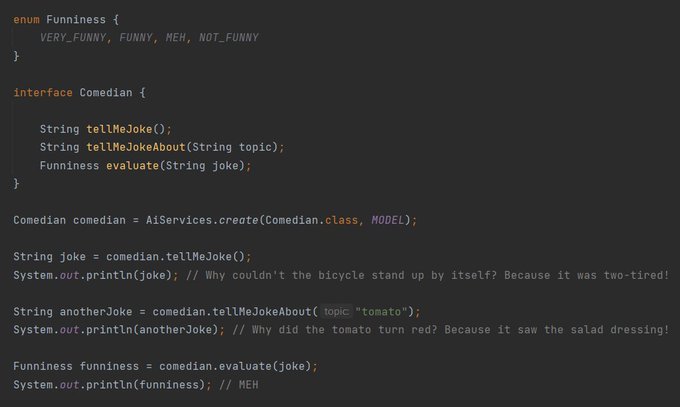
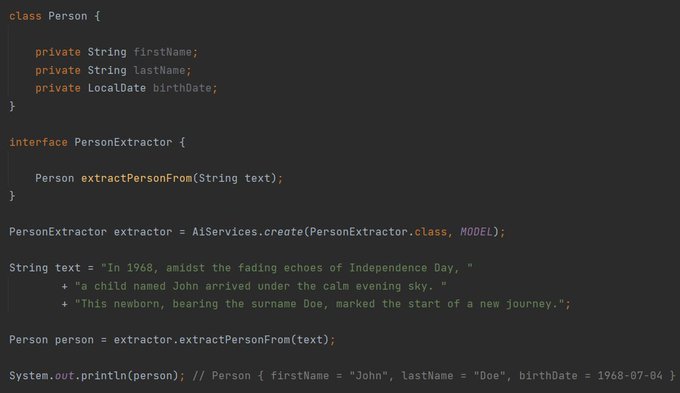
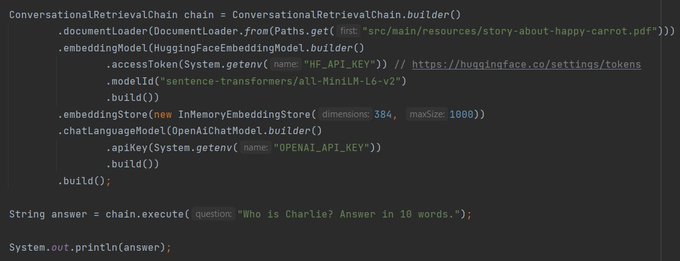
LangChain4j
@langchain4j
2,144
Followers
697
Following
17
Media
608
Statuses
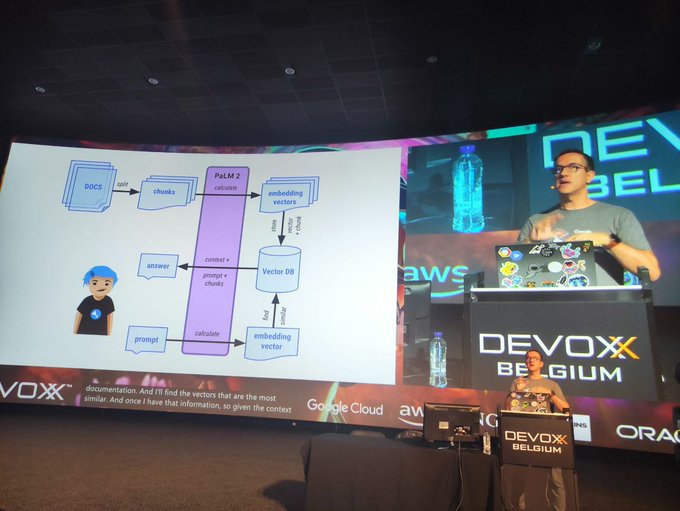
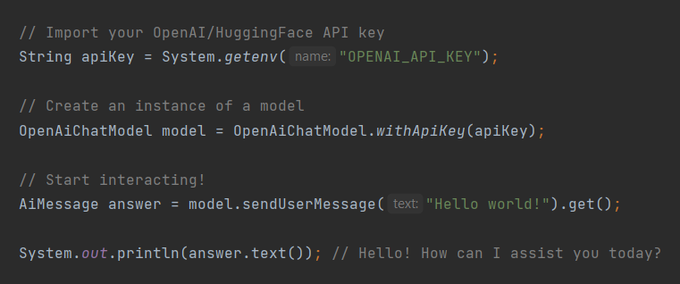
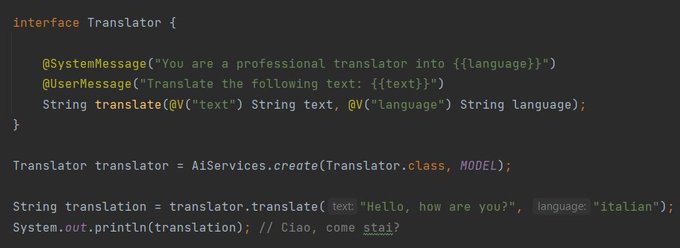
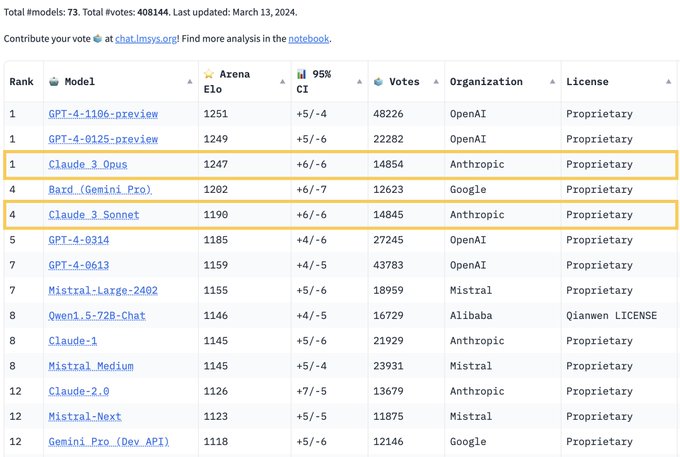
Build LLM-powered applications in Java, Quarkus and Spring Boot. Chatbots, agents, RAG and much more!
Don't wanna be here?
Send us removal request.