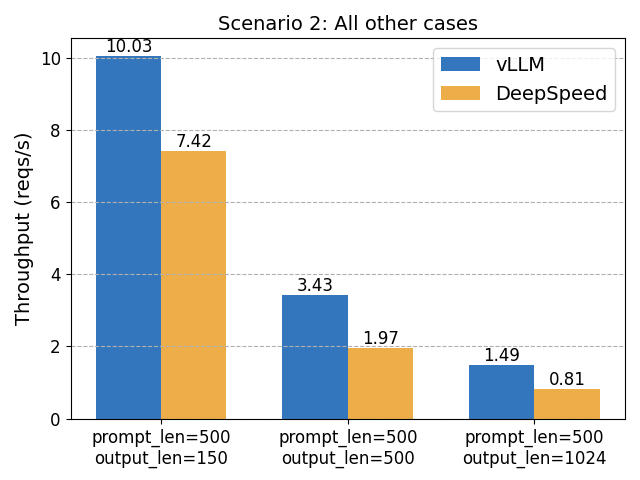
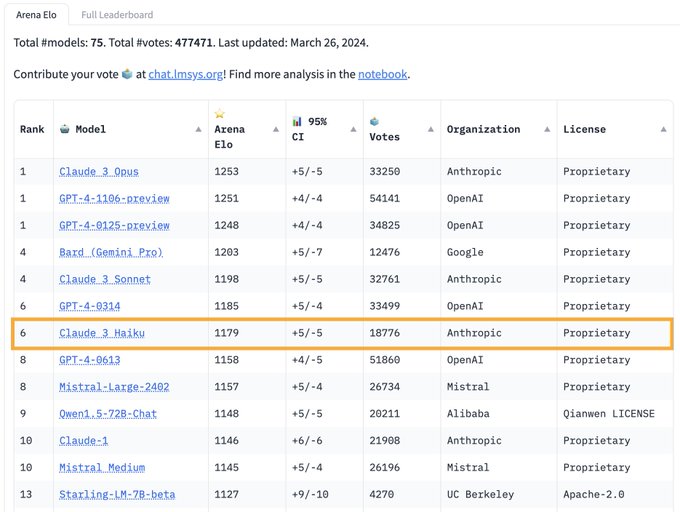
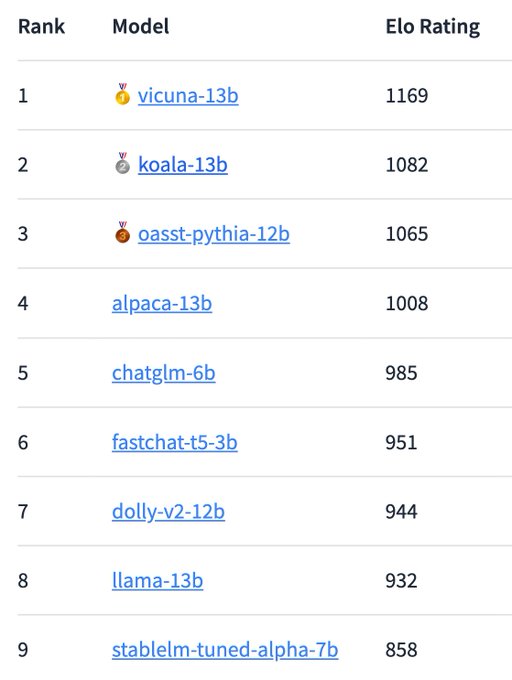
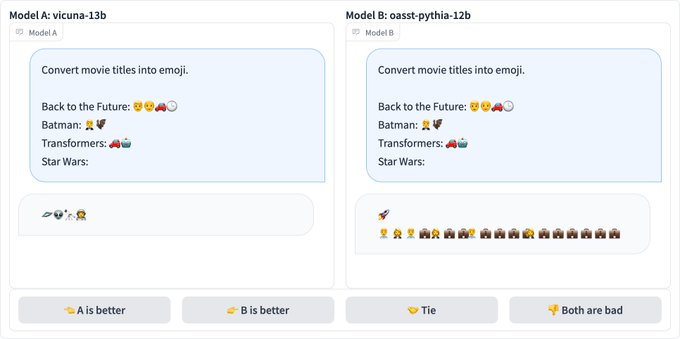
Hao Zhang
@haozhangml
2,924
Followers
275
Following
3
Media
330
Statuses
Asst. Prof. @HDSIUCSD and @ucsd_cse running @haoailab . Cofounder and runs @lmsysorg . 20% with @SnowflakeDB
Don't wanna be here?
Send us removal request.