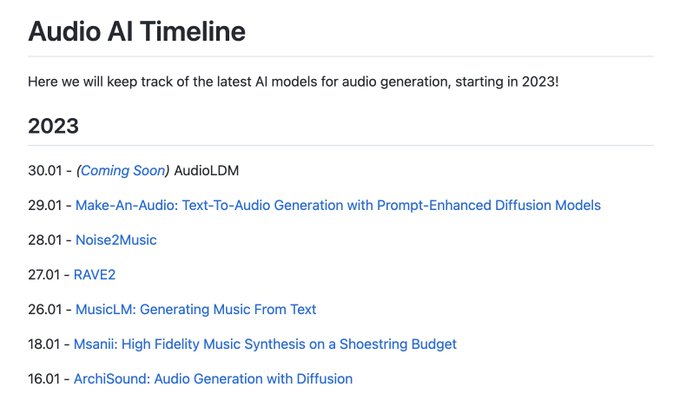
Flavio Schneider
@flavioschneide
3,042
Followers
215
Following
20
Media
47
Statuses
audio and music @elevenlabsio
Don't wanna be here?
Send us removal request.