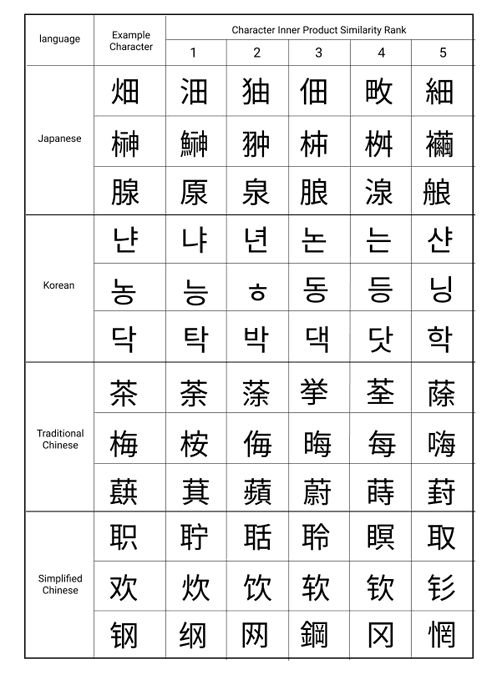
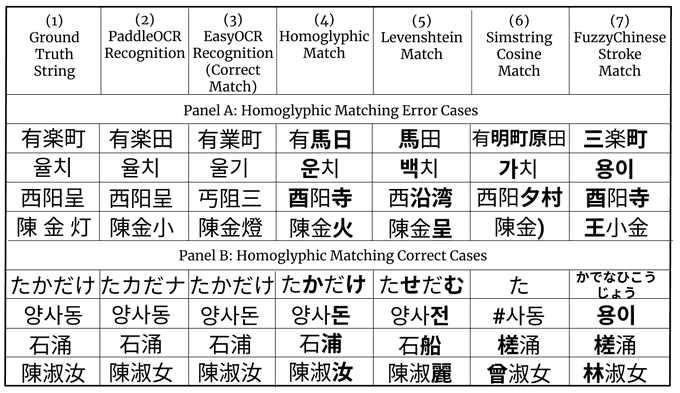
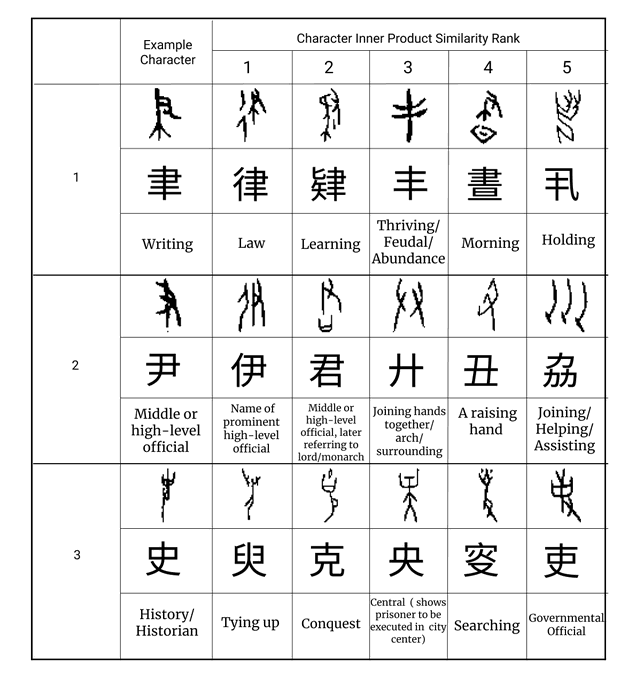
Melissa Dell
@MelissaLDell
12,188
Followers
11
Following
32
Media
107
Statuses
Economics Professor @Harvard . Development economics, political economy, economic history, deep learning methods for data curation.
Cambridge, MA
Joined March 2021
Don't wanna be here?
Send us removal request.