Brendan Bycroft
@BrendanBycroft
3,319
Followers
543
Following
27
Media
77
Statuses
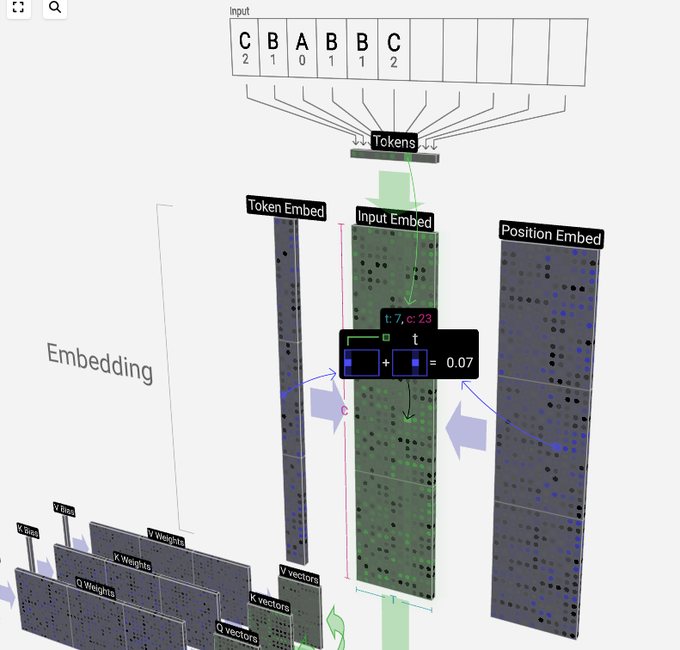
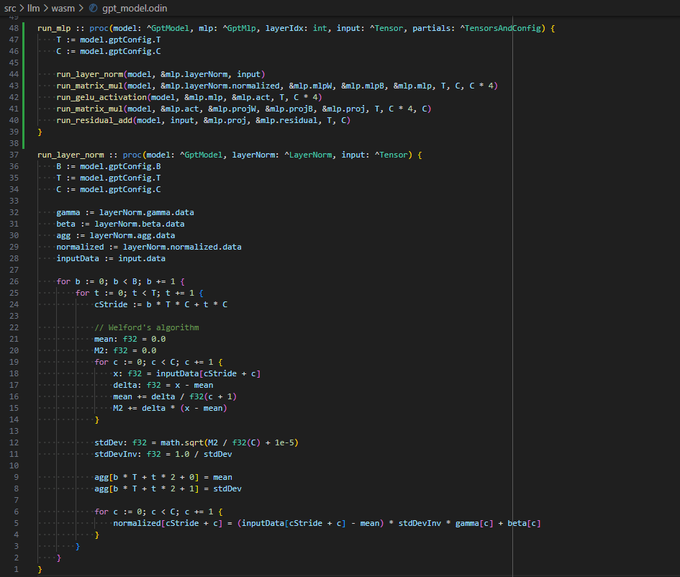
kiwi, on a random walk. LLM Viz --
Don't wanna be here?
Send us removal request.