
🚨 Our New LLM Research 🚨
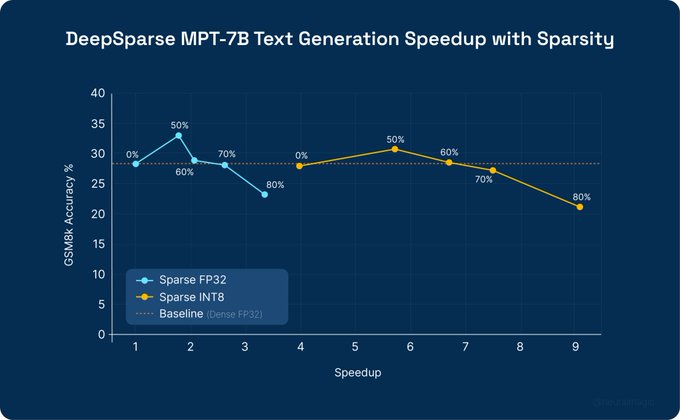
We show how finetuning and sparsity come together to enable accurate LLMs that can be deployed on CPUs with DeepSparse.
The result is a ~7x CPU speedup for a finetuned
@MosaicML
's MPT-7B model vs. the FP32 baseline.
🙏
@ISTAustria
for collaboration!
5
11
42
Replies
Get the paper here:
Kudos to paper authors
@_EldarKurtic
, Denis Kuznedelev,
@elias_frantar
,
@mgoin_
,
@DAlistarh
, and wider teams from Neural Magic and ISTA for this remarkable work!

1
2
9
For a quick paper summary and the impact of this research on the industry, read
@robertshaw21
's recent blog:
1
0
4
Want to try it out on your CPUs today? Go to the DeepSparse GitHub repo and find the steps in the README.

0
0
6

@neuralmagic
@MosaicML
@ISTAustria
Cool, any tokens per seconds benchmarks for Llama2 70B on Intel cpus?
1
0
2


@neuralmagic
@MosaicML
@ISTAustria
2x improvement from sparsity, right ? 3.x improvement is from f32 dense to int8 dense ? == 7x
0
0
0