
Accelerate your
@huggingface
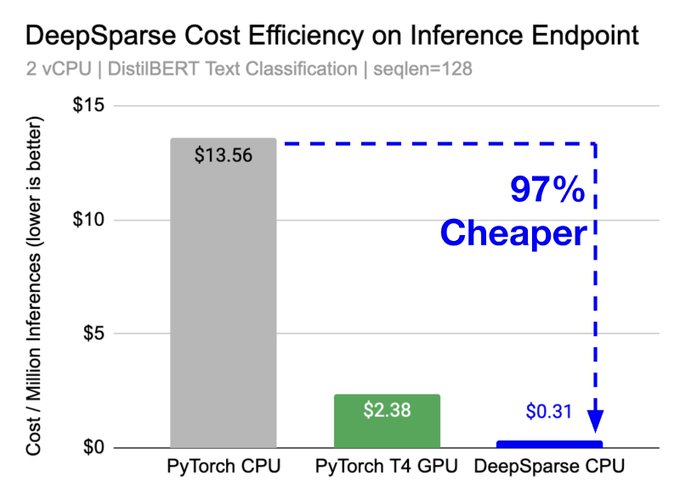
🤗 Inference Endpoints with DeepSparse to achieve 43x CPU speedup and 97% cost reduction over
@PyTorch
.
Side note: DeepSparse is even faster than a T4 GPU 🤯
Learn more in our blog:
12
87
574
Replies


@neuralmagic
@huggingface
@PyTorch
This is very interesting. Looking at SparseZoo, it appears that you are not able to sparsify MobileNetV2 as well as GPT2. Is there any reason for this?
1
0
1

1
0
0

@neuralmagic
@huggingface
@PyTorch
Compare it with ONNX optimized graphs used with TritonRT for proper benchmarking, not the baselines
0
0
0


@neuralmagic
@huggingface
@PyTorch
Impressive. For a moment I read it beats TPUs. I guess Neural Magic will get there one day.
0
0
0

@neuralmagic
@huggingface
@PyTorch
Q:
What’s the perf loss from sparsification?
If I have a tflite network with inference scripts, can I try it with your tools and and see how much sparsity can be achieved?
Do we get the source to the inference libraries you generate?
have you considered any hw acceleration?
1
0
0
