
Accelerate your
#NLP
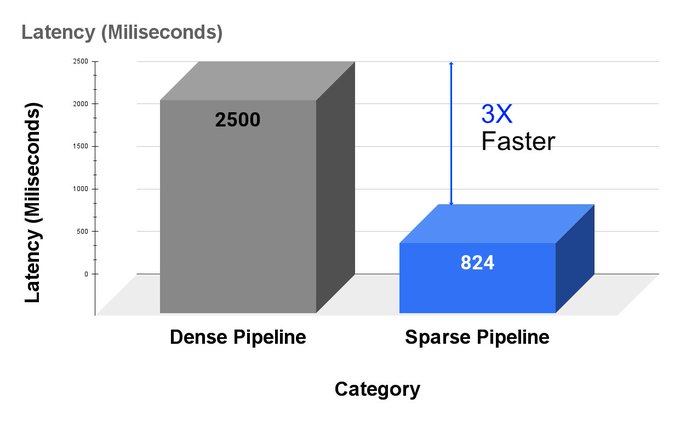
pipelines with sparse transformers! You can get 3x
#CPU
performance increase by optimizing your models with only a few lines of code.
1/3
2
8
73
Replies
1. Pick an already-optimized NLP model from the SparseZoo:
2. Apply your data with a few lines of code using open-source SparseML libraries:
3. Deploy on CPUs using the freely-available DeepSparse:
2/3
1
0
6
You can apply our optimizations to a verity of your CV and NLP use cases to increase performance and decrease deployment costs.
Here’s a document search example use case:
For more use cases, visit our blog:
3/3
0
0
6

@RobFlynnHere
You should be able to run text decoder models in DeepSparse, our CPU inference runtime. Give it a shot! And let us know how it goes via GitHub Issues:
Or in our community Slack where our engineers and the wider community can help:

0
0
1