
🔍 What Starling-LM-7B-beta's excellent performance tells us about benchmarks
I compared the performance of
@NexusflowX
's model across various benchmarks.
In the Chatbot Arena Leaderboard (), this 7B model impressively outperforms many larger models,…
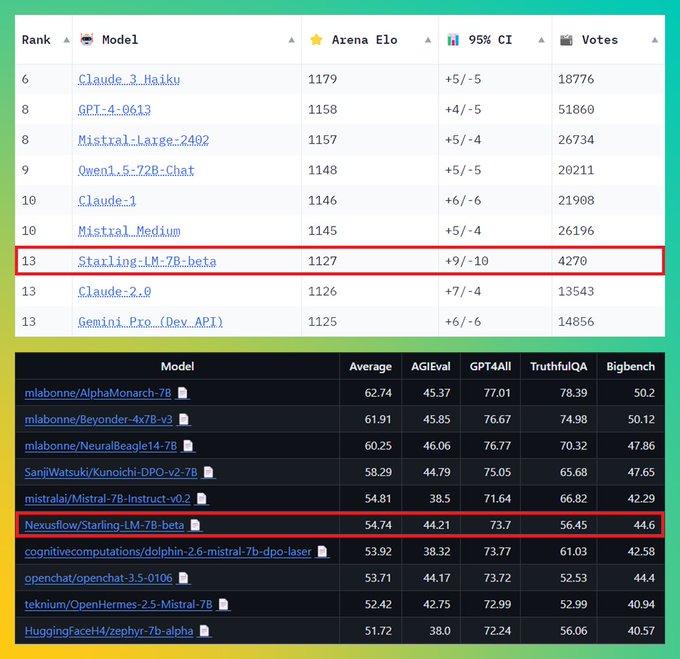
8
26
186
Replies

@maximelabonne
@NexusflowX
Wonderful analysis!
Another interesting point of comparison is IFEval (measure of helpfulness) where Starling scores 44% while Mistral/Mixtral Instruct score ~54%
To me, this suggests the arena has a mild bias against “uncensored” models that follow user intent to the letter
1
0
9

@maximelabonne
@NexusflowX
I had the opposite interpretation of this result: that Arena Elo is failing to capture the holistic capabilities of the model, and/or they figured out how to exploit human preference.
1
0
3
@sam_paech
@NexusflowX
Yes it's completely possible, but I'm cautious about "exploiting human preferences" (like verbosity). In the end, that's what people want so it's difficult to say it's truly exploiting anything (although I agree it's kind of hacking it).
2
0
2

@maximelabonne
@NexusflowX
I agree that despite Starling-LM-7B-beta's good benchmark results, it is not that good model for real chat. Nous-Hermes-2-Mistral-7B-DPO or perhaps the PRO version is better. By the way, are you planning to add these hermes models into your benchmark?
2
0
2

@maximelabonne
@NexusflowX
This week has been crazy. Where's the newsletter just about open source AI news?
0
0
1

@maximelabonne
@NexusflowX
This is great.
We looked at length bias in Arena when working on Alpaca and it’s not that strong actually
I think it was around 0.15 spearman
(That’s why alpaca had to be length controlled cause in that benchmark it was way more pronounced than in Arena leaderboard)
1
0
2

@maximelabonne
@NexusflowX
I tried it and was not impressed, I'll play with it a bit more, but for now my go to general local model is Hermes 2 pro, I'm really impressed by it.
0
0
1

@maximelabonne
@NexusflowX
Nowadays, it seems all Mistral-class 7B models can hold a valid conversation, and the chat arena simply captures human preference of output styles - I.e bullet points raise score, numbered lists raise score, etc. but what’s more interesting to me is instruction following.
1
0
0