
Human feedback on poor dialog system performance is important for the development of
#ConvAI
. 👍👎
But datasets with free-text human feedback are scarce. Can data augmentation come to the rescue?
A 🧵 on one of our
#EMNLP2023
papers (1/11).
📰
#NLProc
2
0
12
Replies
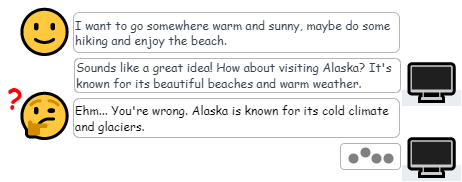
Our findings provide new insights into the composition of the examined datasets, including error types, user response types, and the relations between them. (2/🧵)
#EMNLP2023
1
0
3
Learning from free-text human feedback improves user acceptance. However, the lack of available datasets, i.e., annotations for errors in system utterances and following free-text human feedback, hinders research. (3/🧵)
1
0
3
Recently, data augmentation using synthetic data generation has shown promise, but they usually require the information to be included in the seed data. (4/🧵)
#EMNLP2023
1
0
3
And it is an open question to what extent existing dialog datasets contain errors in system utterances and free-text human feedback. (5/🧵)
#EMNLP2023
1
0
3
In this paper by
@PetrakDominic
,
@NafiseSadat
(
@SheffieldNLP
), Ye Tian &
@ai_nikolai
(both
@wluper_
) and
@IGurevych
(
@UKPLab
), we investigate this question for six commonly used dialog datasets, such as MultiWoZ, SGD, and Wizards-of-Wikipedia. (6/🧵)
#EMNLP2023
1
0
3
@PetrakDominic
@NafiseSadat
@SheffieldNLP
@ai_nikolai
@wluper_
@IGurevych
We use our insights to derive new and broadly applicable taxonomies for the annotation of errors in system utterances and free-text user feedback addressing them. (7/🧵)
#EMNLP2023
1
0
3
@PetrakDominic
@NafiseSadat
@SheffieldNLP
@ai_nikolai
@wluper_
@IGurevych
We investigate the impact of such data into response generation using three SOTA language generation models, including LLaMA, GPT-2 and Flan-T5. (8/🧵)
#EMNLP2023
1
0
3
@PetrakDominic
@NafiseSadat
@SheffieldNLP
@ai_nikolai
@wluper_
@IGurevych
Our experiments show that including free-text human feedback has a positive impact in response generation and that including the erroneous system utterance might be beneficial as well. (9/🧵)
#EMNLP2023

1
0
3
@PetrakDominic
@NafiseSadat
@SheffieldNLP
@ai_nikolai
@wluper_
@IGurevych
We provide open access to our code and results:
Code ➡️
(10/🧵)
#EMNLP2023
1
0
3
@PetrakDominic
@NafiseSadat
@SheffieldNLP
@ai_nikolai
@wluper_
@IGurevych
Consider following our authors
@PetrakDominic
,
@NafiseSadat
(
@SheffieldNLP
), Ye Tian &
@ai_nikolai
(both
@wluper_
) and
@IGurevych
(
@UKPLab
), if you are interested in any updates.
See you in Singapore 🇸🇬! (11/11)
#EMNLP2023
📰

0
0
4