
Our new paper uses deep learning to find coordinates to globally transform a nonlinear PDE to a linear PDE! Read about choosing a good architecture & diverse training data. Cautionary tale about extrapolation. W/ Craig Gin,
@eigensteve
, and Nathan Kutz.
6
58
271
Replies

@BethanyLusch
@eigensteve
What distinguishes this from your previous nature paper? At a first glance they look quite similar.
(Not to read passive-aggressively! :D )
1
0
2
@PatrickKidger
@eigensteve
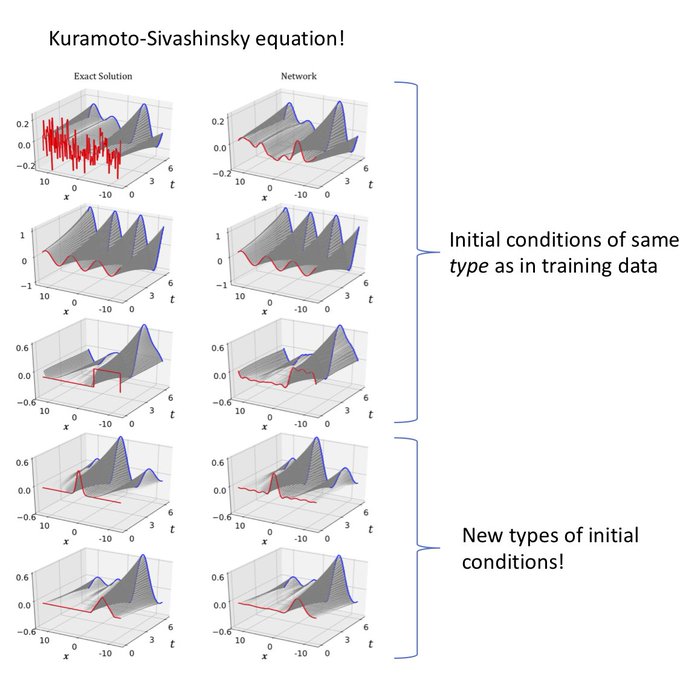
The first paper was small systems of ODEs. Here we apply these ideas to PDEs. Since the space is much bigger (such as 128 spatial points), we need to dive more into being smart about diverse training data and appropriate neural architectures.
1
0
2

@jpjones51
@eigensteve
Great question! Our transformation applies across the domain, so one angle is that you can map into the new coordinates, solve the system or apply a control law, and map what you did back into the original space. You can also check out
@IgorMezic
's work with Koopman.
0
0
1


@BethanyLusch
@eigensteve
Re: diverse training for learning PDEs, I made this formal in .
This is really critical for understanding what your data can/can't tell you about the physics + how to know your predictions are right/wrong *without* having to run the real thing anyways!

1
0
2

