
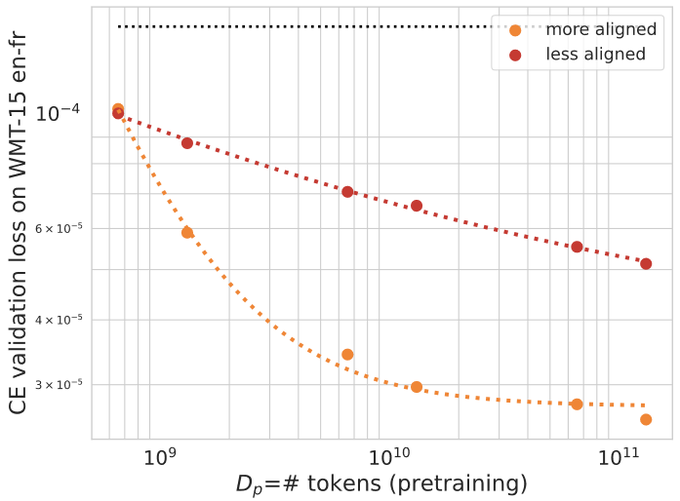
However, there are also cases where moderate misalignment causes the BLEU score to fluctuate or get worse with more pretraining, whereas downstream cross-entropy monotonically improves. 5/6
2
0
4
Replies
Very excited to share the paper from my last
@GoogleAI
internship: Scaling Laws for Downstream Task Performance of LLMs.
w/ Natalia Ponomareva,
@hazimeh_h
, Dimitris Paparas, Sergei Vassilvitskii, and
@sanmikoyejo
1/6

7
28
326
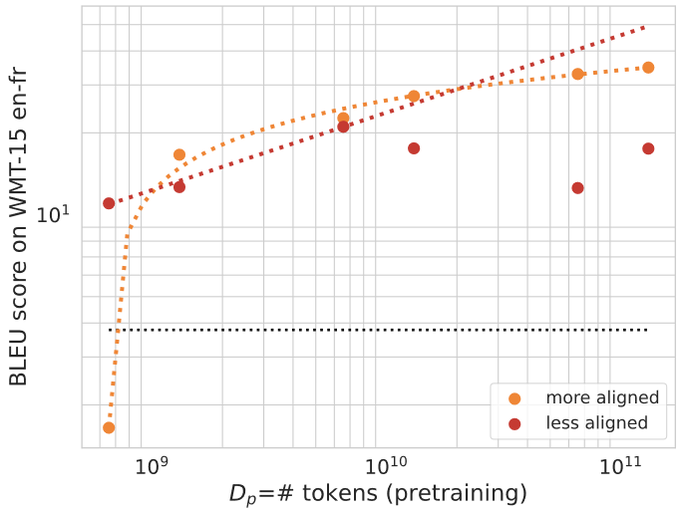
We study the scaling behavior in a transfer learning setting, where LLMs are finetuned for translation tasks, and investigate how the choice of the pretraining data and its size affect downstream performance as judged by two metrics: downstream cross-entropy and BLEU score. 2/6
1
0
4
TLDR: The size of the finetuning dataset and the distribution alignment between the pretraining and downstream data significantly influence the scaling behavior. 3/6
1
0
6
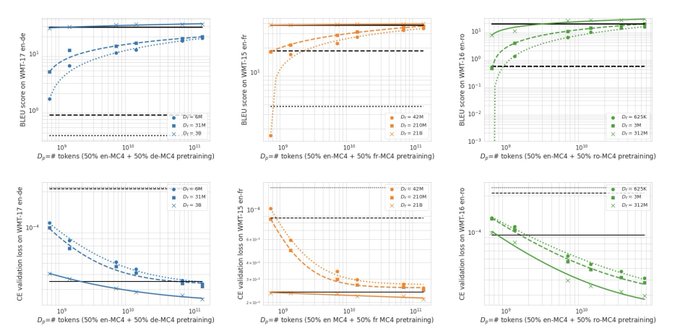
With sufficient alignment, both downstream cross-entropy and BLEU score improve monotonically with more pretraining data. In such cases, we show that it is possible to predict the downstream BLEU score with good accuracy using a log-law. 4/6
1
1
3
This highlights the importance of studying downstream performance metrics and not making decisions solely based on cross-entropy! 6/6
0
0
4
