
Throughout the manuscript, we highlighted the advantages of having a stochastic mask training approach rather than a deterministic one in terms of accuracy, bitrate, and privacy. 5/6
1
0
4
Replies
Excited to share our new work, "Sparse Random Networks for Communication-Efficient Federated Learning".
1/6
1
6
43
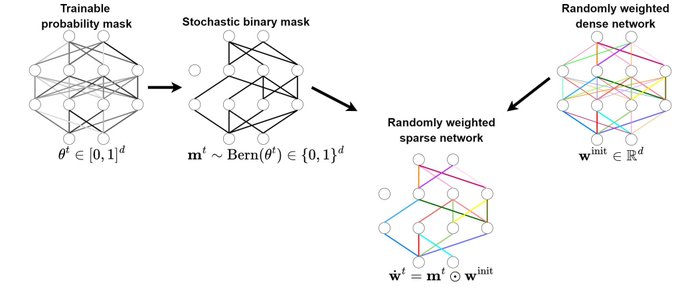
We propose Federated Probabilistic Mask Training (FedPM) that does not update the randomly initialized weights at all. Instead, FedPM freezes the weights at their initial random values and learns how to sparsify the random network for the best performance. 2/6
1
0
5
To this end, the clients collaborate in training a stochastic binary mask to find the optimal sparse random network within the original one. At the end of the training, the final model is a sparse network with random weights – or a subnetwork inside the dense random network. 3/6
1
0
4
FedPM reduces the communication cost to less than 1 bit per parameter (bpp), reaches higher accuracy with faster convergence than the relevant baselines, outputs a final model with size less than 1 bpp, and can potentially amplify privacy. 4/6
1
0
4