
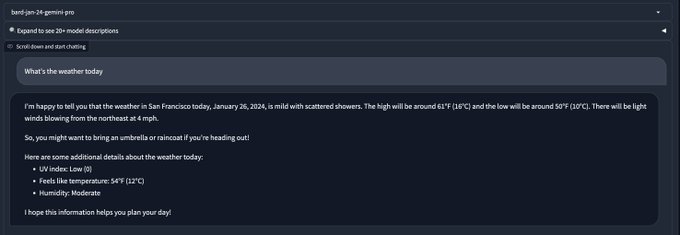
Not sure if that's a fair comparison when bard is using search API while GPT-4 and other models are not (example below). The baremetal Gemini Pro API seems to be in between Mixtral 8*7B and GPT-3.5. So the key difference is search that greatly improves human preference?

🔥Breaking News from Arena
Google's Bard has just made a stunning leap, surpassing GPT-4 to the SECOND SPOT on the leaderboard! Big congrats to
@Google
for the remarkable achievement!
The race is heating up like never before! Super excited to see what's next for Bard + Gemini…

154
628
3K
6
10
60
Replies

@BanghuaZ
@jeremyphoward
I was excited at first but upon closer inspection it is clear they are comparing apples to oranges.
0
0
0

@BanghuaZ
Perplexity Online is using search api too in Chatbot Arena.
(Try asking about recent events)
I think it’s “fair” in a sense that they separate the Gemini API from Bard. So we can compare.
Many things are diff on Arena. Params, MoE/not, closed/open
Very important that Bard is available for FREE on
- Yes, it might use RAG or other techniques in the background that OpenSource models don't
- But GPT-4, Claude & Mistral Medium are closed too. Cannot see under the hood either
- Bard is the only free one!
5
5
61
1
0
4

@BanghuaZ
I have to admit, beyond what you’re saying, I think it’s in the best interests of society if Google fades away. They gave us a bunch, but they stopped improving humanity a long time - Google search is a joke these days that only returns an alternating list of topic summaries.
0
0
0

